

Мода выборки
Иногда важно знать не среднее арифметическое выборки, а то, какая из ее вариант встречается наиболее часто. Так, при управлении магазином одежды менеджеру не важен средний размер продаваемых футболок, а необходима информация о том, какие размеры наиболее популярны
Для этого используется такой показатель, как мода выборки.

В примере с математическим тестом сразу 3 ученика набрали по 13 баллов, а частота всех других вариант не превысила 2, поэтому мода выборки равна 13. Возможна ситуация, когда в ряде есть сразу две или более вариант, которые встречаются одинаково часто и чаще остальных вариант. Например, в ряде
1, 2, 3, 3, 3, 4, 5, 5, 5
варианты 3 и 5 встречаются по три раза. В таком случае ряд имеет сразу две моды – 3 и 5, а всю выборку именуют мультимодальной. Особо выделяется случай, когда в выборке все варианты встречаются с одинаковой частотой:
6, 6, 7, 7, 8, 8.
Здесь числа 6, 7 и 8 встречаются одинаково часто (по два раза), а другие варианты отсутствуют. В таких случаях говорят, что ряд не имеет моды.
Зачем нужна статистика
Ключевой принцип рассматриваемой науки – это получение выводов путем их анализа. Статистика выступает в качестве разновидности математики. Она задействует формулы при расчетах.
Машинное обучение и некоторые другие области IT зародились из статистики. В качестве основы используемых алгоритмов и моделей выступает статистическое обучение. Если с ним разобраться, можно достаточно быстро освоить МО и иные инновационные направления в соответствующей области.
Также статистика поможет разобраться, какие данные можно проанализировать тем или иным способом. А еще – как лучше проводить исследования и анализировать имеющиеся материалы с минимальными потерями /погрешностями.
15.3 Асимметрия
Коэффициент асимметрии (skewness) характеризует симметричность распределение относительно среднего значения. Как мы говорили , коэффициент асимметрии связан c третьим центральным моментом распределения, поэтому выборочный коэффициент асимметрии также рассчитывается на его основе.
\[
\text{skew}(X) = \frac{m_3}{s^3} = \frac{\frac{1}{n} \sum_{i=1}^n (\bar x — x_i)^3}{\big(\frac{1}{n-1} \sum_{i=1}^n (\bar x — x_i)^2\big)^{3/2}},
\]
где \(\bar x\) — выборочное среднее, \(s\) — выборочное стандартное отклонение, \(m_3\) — выборочный третий центральный момент.
Коэффициент асимметрии может принимать положительные и отрицательные значения, а также быть равным нулю.
- положительный коэффициент асимметрии (positive skew) указывает на наличие длинного правого хвоста распределения, соответственно всё распределение будет скошено влево (то есть преобладают низкие значения)
- отрицательный коэфффициент асимметрии (negative skew) указывает на наличие длинного левого хвоста распределения, соответственно всё распределения будет скошено вправо (то есть преобладают высокие значения)
- значения коэффициента асимметрии, близкие к нулю, говорят о симметричности распределения
Дилемма (компромисс) смещения и дисперсии
Смещение и дисперсия вместе составляют итоговую ошибку предсказания модели машинного обучения. В идеальном мире и смещение маленькое, и дисперсия низкая. На практике это связано в дилемму: уменьшение одной из величин неизбежно приводит к росту другой.

Если не вдаваться в детали, обучение модели — это построение функции, график которой лучше всего ложится на точки из тренировочного набора данных.
Модель может нарисовать нам довольно сложную и заковыристую функцию, график, который хорошо охватывает все точки в тренировочных данных. Но если наложить этот график на новые точки (то есть дать функции новые данные), она сработает хуже — так и получается смещение.

Иллюстрация: mofusand
С другой стороны, обучение на разных тренировочных наборах или даже разных датасетах с большой вероятностью даст разброс в предсказаниях, то есть высокую дисперсию.
Более сложные модели дают низкое смещение, но чувствительны к шуму и колебаниям в новых данных, поэтому их предсказания разбросаны. Если при обучении наш снайпер будет учитывать незначимые факторы (вроде цвета мишени или направления магнитного поля Земли), то в другом тире, с другой винтовкой или в другую погоду точность его стрельбы упадёт.
Простые модели, напротив, упускают важные параметры и «бьют кучно, но мимо»
Как другой снайпер, не приученный обращать внимание на ветер и расстояние до мишени
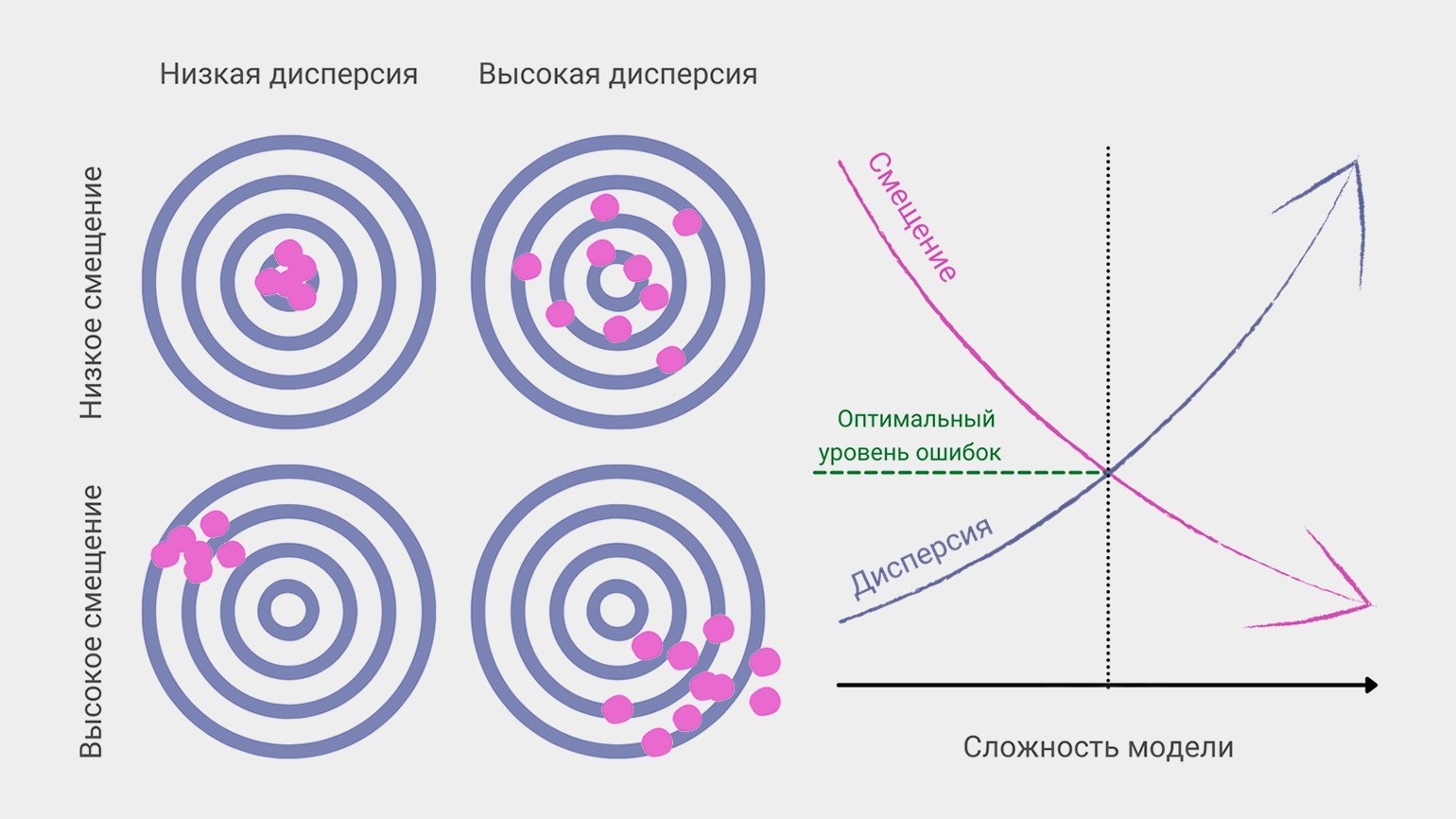
В процессе настройки модели машинного обучения дата-сайентист всегда ищет компромисс между смещением и дисперсией, чтобы уменьшить общую ошибку предсказания.
Кстати, эта дилемма встречается не только в статистике и машинном обучении, но и в обучении людей. В исследовании 2009 года утверждается, что люди используют эвристику «высокое смещение + низкая дисперсия»: мы заблуждаемся, зато очень уверенно.
Учтите это, если захотите сделать свой ИИ более похожим на человека.
Относительная частота
Относительная частота это в принципе та же самая частота, которая была рассмотрена ранее, но только выраженная в процентах.
Относительная частота равна отношению частоты на общее число элементов выборки.
Вернемся к нашей таблице:

Пять подтягиваний выполнили 4 человека из 36. Шесть подтягиваний выполнили 5 человек из 36. Восемь подтягиваний выполнили 10 человек из 36 и так далее. Давайте заполним таблицу с помощью таких отношений:

Выполним деление в этих дробях:

Выразим эти частоты в процентах. Для этого умножим их на 100. Умножение на 100 удобно выполнить передвижением запятой на две цифры вправо:

Теперь можно сказать, что пять подтягиваний выполнили 11% участников, 6 подтягиваний выполнили 14% участников, 8 подтягиваний выполнили 28% участников и так далее.
Понравился урок? Вступай в нашу новую группу Вконтакте и начни получать уведомления о новых уроках
15.4 Эксцесс
Коэффиент эксцесса (excess kurtosis) показывает отсроту пика распределения. Как мы говорили , коэффициент эксцесса связан с четвертым центральным моментом распределения, поэтому выборочный коэффициент эксцесса также рассчитывается на его основе.
\
Что в формуле коэффициента эксцесса делает \(-3\)?
Коэффициент эксцесса, как и коэффициент асимметрии, может принимать положительные, отрицательные или нулевые значения.
- нулевой коэффициент эксцесса обозначает такой же эксцесс, как у стандартного нормального распределения (то есть, «нормальный»)
- положительный коэффициент эксцесса обозначает, что распределение имеет более острую вершину (то есть у нас очень много средних значений, но тонкие «хвосты» — мало низких и высоких значений)
- отрицательный коэффициент эксцесса обозначает, что распределение имеет более пологую вершину (то есть у нас меньше средних значений и толстые «хвосты» — много низких и высоких значений)
Средняя скорость движения
При изучении задач на движение мы определяли скорость движения следующим образом: делили пройденное расстояние на время. Но тогда подразумевалось, что тело движется с постоянной скоростью, которая не менялась на протяжении всего пути.
В реальности, это происходит довольно редко или не происходит совсем. Тело, как правило, движется с различной скоростью.
Когда мы ездим на автомобиле или велосипеде, наша скорость часто меняется. Когда впереди нас помехи, нам приходиться сбавлять скорость. Когда же трасса свободна, мы ускоряемся. При этом за время нашего ускорения скорость изменяется несколько раз.
Речь идет о средней скорости движения. Чтобы её определить нужно сложить скорости движения, которые были в каждом часе/минуте/секунде и результат разделить на время движения.
Задача 1. Автомобиль первые 3 часа двигался со скоростью 66,2 км/ч, а следующие 2 часа — со скоростью 78,4 км/ч. С какой средней скоростью он ехал?

Сложим скорости, которые были у автомобиля в каждом часе и разделим на время движения (5ч)
![]()
Значит автомобиль ехал со средней скоростью 71,08 км/ч.
Определять среднюю скорость можно и по другому — сначала найти расстояния, пройденные с одной скоростью, затем сложить эти расстояния и результат разделить на время. На рисунке видно, что первые три часа скорость у автомобиля не менялась. Тогда можно найти расстояние, пройденное за три часа:
66,2 × 3 = 198,6 км.
Аналогично можно определить расстояние, которое было пройдено со скоростью 78,4 км/ч. В задаче сказано, что с такой скоростью автомобиль двигался 2 часа:
78,4 × 2 = 156,8 км.
Сложим эти расстояния и результат разделим на 5
![]()
Задача 2. Велосипедист за первый час проехал 12,6 км, а в следующие 2 часа он ехал со скоростью 13,5 км/ч. Определить среднюю скорость велосипедиста.

Скорость велосипедиста в первый час составляла 12,6 км/ч. Во второй и третий час он ехал со скоростью 13,5. Определим среднюю скорость движения велосипедиста:
![]()
Погрешности выборки
Погрешности выборки характеризуют, насколько значительная ошибка допущена при замещении генеральной совокупности выборкой. Сколь бы тщательно ни подбирали выборку, параметр генеральной совокупности и оценка выборки Т всегда будут отличаться. Их разница является погрешность выборки .
Среднюю стандартную погрешность выборки находят по формуле
(11)
Средняя стандартная погрешность выборки характеризует рассеяние средних арифметических выборки по отношению к средним генеральной совокупности: чем больше погрешность, тем дальше среднее арифметическое выборки может находиться от среднего генеральной совокупности. В свою очередь, чем меньше погрешность, тем ближе к среднему генеральной совокупности находится среднее выборки. При увеличении числа наблюдений n стандартная погрешность уменьшается.
Стандартную погрешность называют также абсолютной погрешностью средней величины и нередко записывают .
Пример 6. Найти стандартную погрешность средней урожайности сельских хозяйств и интервал оценки, используя результаты примеров 2 и 4.
Решение. В примере 2 найдена средняя урожайность зерновых, равная 15,6 центнеров с га. В примере 4 найдена дисперсия урожайности, равная 57,2. Найдём стандартное отклонение урожайности:
Найдём теперь стандартную погрешность:
Интервал оценки средней урожайности:
| Назад | Листать | Вперёд>>> |
Всё по теме «Математическая статистика»
Среднее арифметическое выборки
Сбор информации о выборке является лишь первой стадией статистического исследования. Далее ее необходимо обобщить, то есть получить некоторые цифры, характеризующие выборку. Самой часто используемой статистической характеристикой является среднее арифметическое.

Другими словами, для подсчета среднего арифметического необходимо просто сложить все числа в ряде данных, а потом поделить получившееся значение на количество чисел в ряде. Так, в примере с тестом по математике (таблица 1) средний балл учащихся составит: (12+19+19+14+17+16+18+20+15+25+13+20+25+16+17+12+24+13+21+13):20=
= 349:20 = 17,45.
Среднее арифметическое позволяет одним числом характеризовать какое-либо качество всех объектов группы. Чем больше средний балл учащихся в классе, тем выше их успеваемость. Чем меньше среднее количество голов, пропускаемых футбольной командой за один матч, тем лучше она играет в обороне. Если средняя зарплата программистов в городе составляет 90 тысяч рублей, а дворников – 25 тысяч рублей, то это значит, что программисты значительно более востребованы на рынке труда, а потому при выборе будущей профессии лучше предпочесть именно эту специальность.
Дисперсия выборки. Стандартное отклонение
Дисперсией величины называется среднее значение квадрата отклонения величины от её среднего значения. Дисперсию генеральной совокупности рассчитывают по формуле:
(4)
Дисперсию выборки рассчитывают по формуле:
(5)
для негруппированных выборок и
(6)
для группированных выборок.
Пример 3. В таблице – данные о возрасте жителей административной территории Т в 2013 году.
Не будем приводить эту таблицу из-за её громоздкости. Отметим лишь, что в таблице дана численность
каждого из возрастов (по одному году, например, 33 года, 40 лет, 65 лет и т.д.) в группах от 0 лет по 94 года (включительно) и численность всей возрастной группы
в интервале 95-99 лет, а также численность жителей старше 100 лет.








Требуется найти средний возраст жителей административной территории и дисперсию среднего возраста.
Решение. Найдём средний возраст. Так как данные в таблице являются данными генеральной совокупности, находим средний возраст генеральной совокупности:
В таблице – данные о числе жителей каждого возраста, исключение же – жители в возрасте 95-99 лет и старше 100 лет. Поэтому рассчитали центр интервала возрастной группы 95-99 лет: 97 лет и в расчётах использовали его.
Так как число жителей старше 100 лет относительно небольшое, чтобы упростить расчёты, нижнюю границу интервала приняли за значение признака.
Итак, средний возраст жителей административной территории Т – 38,2 года
Найдём теперь его дисперсию:
Пример 4. Найти дисперсию урожайности зерновых в сельских хозяйствах, используя данные примера 2.
Решение. Средняя урожайность по выборке составляет 15,6 центнеров с га. Чтобы найти дисперсию, создадим дополнительную таблицу.
|
Центры интервалов |
Число хозяйств |
|||
|
2,5 |
4244 |
-13,1 |
172,1 |
730412,3 |
|
7,5 |
10446 |
-8,1 |
65,9 |
688558,6 |
|
12,5 |
18956 |
-3,1 |
9,7 |
184391,3 |
|
17,5 |
20207 |
1,9 |
3,5 |
71505,7 |
|
22,5 |
8159 |
6,9 |
47,3 |
386328,5 |
|
27,5 |
4165 |
11,9 |
141,2 |
585113,6 |
|
32,5 |
1316 |
16,9 |
285,0 |
375024,0 |
|
37,5 |
792 |
21,9 |
478,8 |
379196,9 |
|
42,5 |
183 |
26,9 |
722,6 |
132234,9 |
|
47,5 |
182 |
31,9 |
1016,4 |
184986,0 |
|
52,5 |
161 |
36,9 |
1360,2 |
218995,1 |
|
Всего |
68791 |
— |
— |
393679,1 |
Теперь у нас есть всё, чтобы найти дисперсию:
Пример 5. Найти дисперсию температуры в населённом пункте N в 2009 году, используя данные примера 1.
Решение. Данная выборка – негруппированная, найдём дисперсию температуры для негруппированной выборки:
Стандартное отклонение равно положительному корню из дисперсии. Стандартное отклонение генеральной совокупности находят по формуле
(7)
Стандартное отклонение выборки находят по формуле
. (9)
для негруппированных выборок и
(10)
для группированных выборок.
15.1 Меры центральной тенденции
Насколько ёмко мы хотим описать наши даннные? Ну, попробуем для начала максимально ёмко и максимально просто — одним числом. Например, самым часто встречающимся наблюдением. Как мы будем это наблюдение искать, зависит от конкретной переменной.







| Шкала | Мера центральная тенденции |
|---|---|
| Номинальная | Мода |
| Порядковая | Медиана |
| Интервальная | Среднее арифметическое |
| Абсолютная | Среднее геометрическое и др. |
15.1.1 Мода
Мода (mode) — наиболее часто встречающееся значение данной переменной.
Тут все достаточно просто и интуитивно понятно. Пусть у нас есть следующий вектор наблюдений:
Если мы составим таблицу частот по этому вектору, то получим следующее:
Очевидно, что \(4\) всречается в векторе чаще других значений — это и есть мода.
Также очевидно, что моду невозможно посчитать на непрерывной шкале.
Почему?
Формально моду можно определить как значение переменной, при котором функция вероятности (probability mass function) принимает максимальное значение:
\
К сожалению, в R нет встроенной функции для расчёта моды.
Напишите функцию, которая принимает на вход вектор значений дискретной переменной, и вычисляет моду данной переменной. Если мод у данной переменной несколько, необходимо вернуть все.
15.1.2 Медиана
Если мы уже гуляем на просторах порядковой шкалы, то можем посчитать медиану.
Медиана (median) — это значение, которые располягается на середине сортированного вектора значений переменной. То есть, она делит все наблюдения переменной ровно пополам и 50% наблюдений оказывается по одну сторону от медианы, а 50% — по другую. По этой причине медиана также называется вторым распределения.
Почему нельзя посчитать медиану на номинальной шкале?
Формальное определение медианы зависит от количества значений в векторе: если есть нечётное количество значений — то это ровно середина сортированного вектора, если есть чётное количество наблюдение — то медиана определяется как (арифметическое) среднее между двумя срединными наблюдениями.
\
где \(X\) — вектор налюдений данной переменной, \(n\) — число наблюдений, \(X(a)\) — наблюдение с индексом \(a\) в сортированном векторе \(X\).
Для вектора , который был создан выше, расчёт медианы выглядит так:
Изи.
Примеры задач на нахождение средней выборки
Пример 2
Выборочная совокупность задана следующей таблицей распределения:
 Рисунок 2.
Рисунок 2.
Найти среднее выборочное данной совокупности.
Решение.
Для нахождения значения выборочной средней будем пользоваться следующей формулой:
\
Обычно, для наглядности и удобности вычислений составляется расчетная таблица, в которую входят необходимые промежуточные вычисления. В нашем случае составим таблицу со следующей «шапкой»:
![]() Рисунок 3.
Рисунок 3.
Внизу таблицы также добавляется строка «итог», в которой подсчитывается сумма по всем значениям столбцов. Проведя необходимые вычисления, получим следующую расчетную таблицу:
 Рисунок 4.
Рисунок 4.
Используя формулу, получим:
\
Ответ: 15,25.
Пример 3
Проводится социальный опрос среди 100 пенсионеров об уровне их пенсии. Получена следующая таблица распределения результатов опроса (размер пенсии указан в тысячах рублей):
 Рисунок 5.
Рисунок 5.
Найти среднее выборочное данной совокупности.
Данная совокупность является выборочной, поэтому будем пользоваться следующей формулой:
\
Составим, для начала, расчетную таблицу.
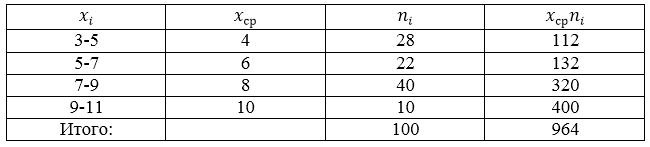 Рисунок 6.
Рисунок 6.
Получаем:
\
Ответ: 9,64.
Мода и медиана
Модой называют элемент, который встречается в выборке чаще других.
Рассмотрим следующую выборку: шестеро спортсменов, а также время в секундах за которое они пробегают 100 метров

Элемент 14 встречается в выборке чаще других, поэтому элемент 14 назовем модой.
Рассмотрим еще одну выборку. Тех же спортсменов, а также смартфоны, которые им принадлежат

Элемент iphone встречается в выборке чаще других, значит элемент iphone является модой. Говоря простым языком, носить iphone модно.
Конечно элементы выборки в этот раз выражены не числами, а другими объектами (смартфонами), но для общего представления о моде этот пример вполне приемлем.
Рассмотрим следующую выборку: семеро спортсменов, а также их рост в сантиметрах:

Упорядочим данные в таблице так, чтобы рост спортсменов шел по возрастанию. Другими словами, построим спортсменов по росту:

Выпишем рост спортсменов отдельно:
180, 182, 183, 184, 185, 188, 190
В получившейся выборке 7 элементов. Посередине этой выборки располагается элемент 184. Слева и справа от него по три элемента. Такой элемент как 184 называют медианой упорядоченной выборки.
Медианой упорядоченной выборки называют элемент, располагающийся посередине.
Отметим, что данное определение справедливо в случае, если количество элементов упорядоченной выборки является нечётным.
В рассмотренном выше примере, количество элементов упорядоченной выборки было нечётным. Это позволило нам быстро указать медиану
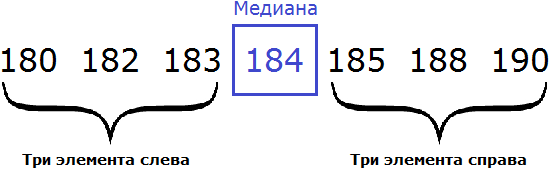
Но возможны случаи, когда количество элементов выборки чётно.
К примеру, рассмотрим выборку в которой не семеро спортсменов, а шестеро:

Построим этих шестерых спортсменов по росту:

Выпишем рост спортсменов отдельно:
180, 182, 184, 186, 188, 190
В данной выборке не получается указать элемент, который находился бы посередине. Если указать элемент 184 как медиану, то слева от этого элемента будут располагаться два элемента, а справа — три. Если как медиану указать элемент 186, то слева от этого элемента будут располагаться три элемента, а справа — два.
В таких случаях для определения медианы выборки, нужно взять два элемента выборки, находящихся посередине и найти их среднее арифметическое. Полученный результат будет являться медианой.
Вернемся к нашим спортсменам. В упорядоченной выборке 180, 182, 184, 186, 188, 190 посередине располагаются элементы 184 и 186

Найдем среднее арифметическое элементов 184 и 186
Элемент 185 является медианой выборки, несмотря на то, что этот элемент не является членом исходной и упорядоченной выборки. Спортсмена с ростом 185 нет среди остальных спортсменов. Рост в 185 см используется в данном случае для статистики, чтобы можно было сказать о том, что срединный рост спортсменов составляет 185 см.
Поэтому более точное определение медианы зависит от количества элементов в выборке.
Если количество элементов упорядоченной выборки нечётно, то медианой выборки называют элемент, располагающийся посередине.
Если количество элементов упорядоченной выборки чётно, то медианой выборки называют среднее арифметическое двух чисел, располагающихся посередине этой выборки.
Медиана и среднее арифметическое по сути являются «близкими родственниками», поскольку и то и другое используют для определения среднего значения. Например, для предыдущей упорядоченной выборки 180, 182, 184, 186, 188, 190 мы определили медиану, равную 185. Этот же результат можно получить путем определения среднего арифметического элементов 180, 182, 184, 186, 188, 190
![]()
Но медиана в некоторых случаях отражает более реальную ситуацию. Например, рассмотрим следующий пример:
Было подсчитано количество имеющихся очков у каждого спортсмена. В результате получилась следующая выборка:
0, 1, 1, 1, 2, 1, 2, 3, 5, 4, 5, 0, 1, 6, 1
Определим среднее арифметическое для данной выборки — получим значение 2,2
![]()
По данному значению можно сказать, что в среднем у спортсменов 2,2 очка
Теперь определим медиану для этой же выборки. Упорядочим элементы выборки и укажем элемент, находящийся посередине:
0, 0, 1, 1, 1, 1, 1, 1, 2, 2, 3, 4, 5, 5, 6
В данном примере медиана лучше отражает реальную ситуацию, поскольку половина спортсменов имеет не более одного очка.
Государство
При входе на сайт Госстатистики пользователь видит структурированную информацию, вверху экрана есть горизонтально расположенная панель с разделами. Каждый из них подписан, и многие обладают выпадающим списком для удобства – не нужно лишний раз кликать.









Достаточно навести курсор на нужный подпункт и один раз выбрать его для перехода. На текущий момент самыми актуальными темами являются:
- Субъекты РФ, их актуальный перечень, группировка в округа, типы и коды.
- Уровень урбанизации.
- Бюджет России.
- Социальные выплаты.
- Формы и виды собственности.
- Внешний и внутренний долг.
- Инвестиции в основной капитал.
Смещение
Аналогично тому, как производится выборка из генеральной совокупности, дата-сайентисты из готового датасета выделяют тренировочный набор. Именно на этой «выборке второго порядка» модель учится делать предсказания.
Прочитайте нашу статью о создании простой модели машинного обучения. Она предсказывает город, в который вероятнее всего поедет турист, на основании его возраста, пола, места жительства, дохода и транспортных предпочтений. Такая рекомендательная система на минималках.
Смещение происходит, когда модель недооценивает или переоценивает какой-либо параметр. Представим, что модель из статьи выше отправляет всех краснодарцев в Париж — независимо от их дохода, предпочтений и других параметров. В этом случае мы скажем, что модель переоценивает значение параметра «Город проживания».
Чаще всего причиной смещения являются:
- неправильный сбор данных в датасет: например, в него попали только краснодарцы — любители Парижа;
- неправильное формирование тренировочного набора из датасета;
- неправильное измерение ошибок.
Когда мы неверно собираем данные, говорят о систематической ошибке отбора. Например, в прошлом веке многие считали, что во Вселенной больше голубых галактик, — впечатление возникало потому, что плёнка была более чувствительна к голубой части спектра.
О доброте дельфинов мы знаем только от спасённых ими людей. Фото: Pixabay
Другая ошибка — ошибка меткого стрелка — происходит, когда мы вольно или невольно отбираем в выборку только схожие между собой данные, то есть фактически рисуем мишень вокруг места, куда попадём.
Причин, вызывающих смещение, так много, что Марк Твен заметил: «Существует три вида лжи: ложь, наглая ложь и статистика». Например:
- Эффект низкой/высокой базы. Если в финансовом отчёте найти самый низкий показатель прибыли, то на его фоне любой другой результат будет выглядеть как достижение. И наоборот: если хотите показать, что ученик перестал прогрессировать, сравнивайте текущие оценки с его лучшими результатами за все годы обучения.
- Сокращение рассматриваемого периода. Если хочется доказать, что рекламная кампания не приносит результатов, надо просто найти период, когда деньги уже потрачены, а эффекта ещё нет. И рассматривать только его.
- Исключение из выборки. Если вы измеряете результативность методики снижения веса, то можно выкидывать из выборки участников, которые отказались от методики, не дойдя до конца. Это существенно «повысит» эффективность методики.
- Ну и, конечно же, классика: «Интернет-опрос населения показал, что 100% населения пользуются интернетом».
Эти и другие ошибки смещения трудно выявить статистическими методами, поэтому нужно стараться избежать их до того, как вы начнёте сбор данных.
Если пить «Боржоми» уже поздно (датасет уже сформирован), обязательно спросите себя: «Не смещены ли мои данные?» — а они наверняка смещены, «Куда и почему они смещены?» и «Можно ли с этим жить?»
Распределение
Внешняя форма данных, выраженная в мерах описательной статистики, даёт нам информацию об их характере. Это как в жизни: по фигуре, походке и одежде человека обычно можно догадаться о его поле, возрасте и даже профессии. В случае числовых данных мы догадываемся о распределении.
Термин пришёл из теории вероятностей, которая рассматривает любое событие в мире как имеющее ту или иную вероятность. Однородные события хоть и происходят с разной вероятностью, но подчиняются распределению, которое «раздаёт» им эти вероятности.
В Data Science распределение понимается обобщённо: это закон соответствия одной величины другой. Оно подсказывает нам, какой именно процесс может скрываться за данными, и то, насколько эти данные полны. Чуть подробнее об этом в нашей статье про математику для джунов.
Возможно, вы уже слышали про колокол нормального распределения, или гауссиану: она описывает процессы, где результат является суммой многих случайных величин, каждая из которых слабо зависит от другой и вносит сравнительно небольшой вклад.
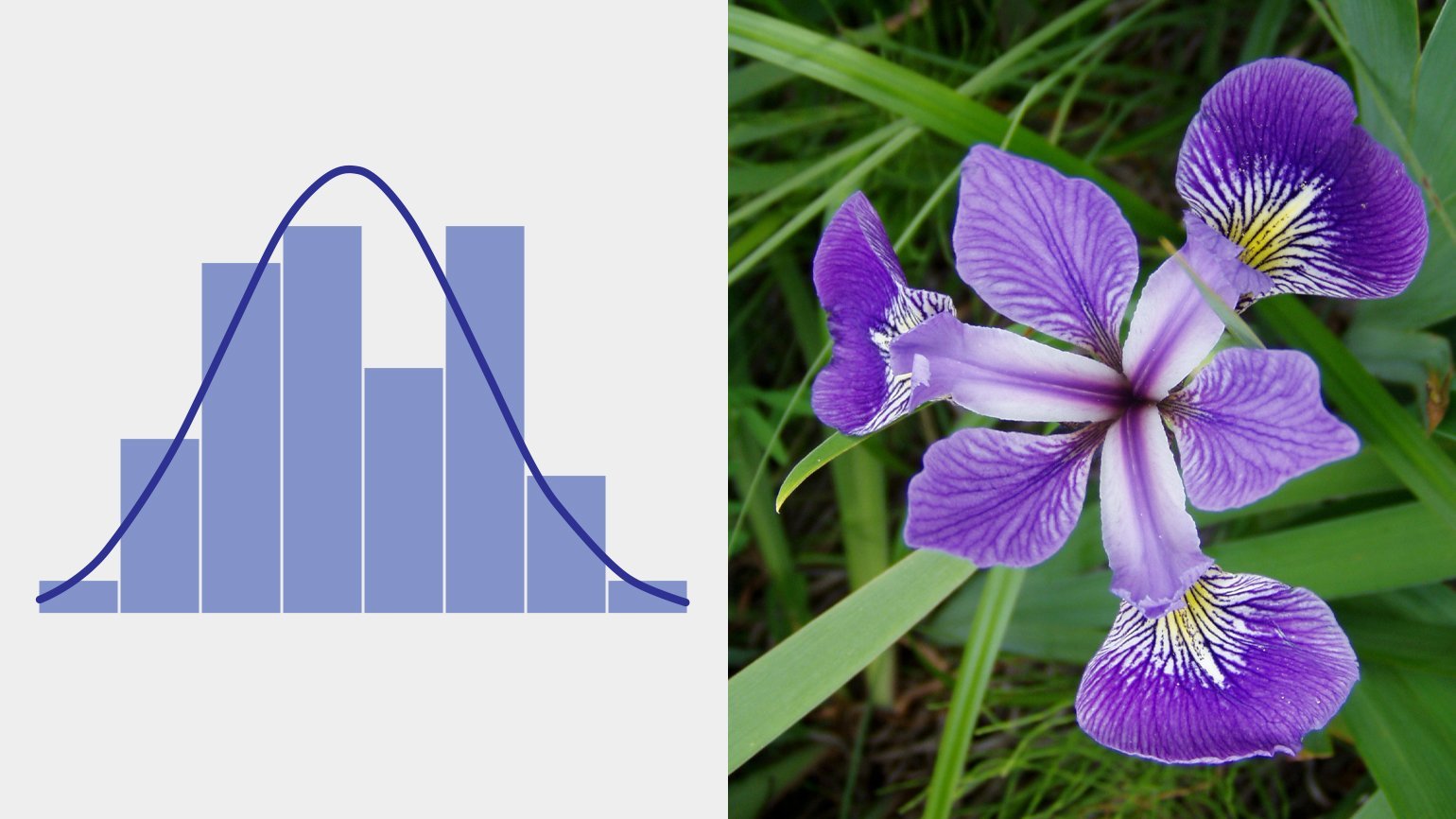
Распределение размеров чашелистика ириса разноцветного. Изображение: Qwfp / Pbroks13 /
Величина ошибок измерения в физике, длина когтей, зубов и шерсти в биологии, объёмы речных стоков в гидрологии — все эти показатели имеют нормальное распределение. Это, пожалуй, самое распространённое в природе и не только в природе распределение, поэтому оно и названо нормальным.
Распределение Пуассона тоже часто встречается в работе дата-сайентистов и аналитиков: это число событий за какой-то промежуток времени — при условии, что события независимы друг от друга и имеют некоторый порог интенсивности.
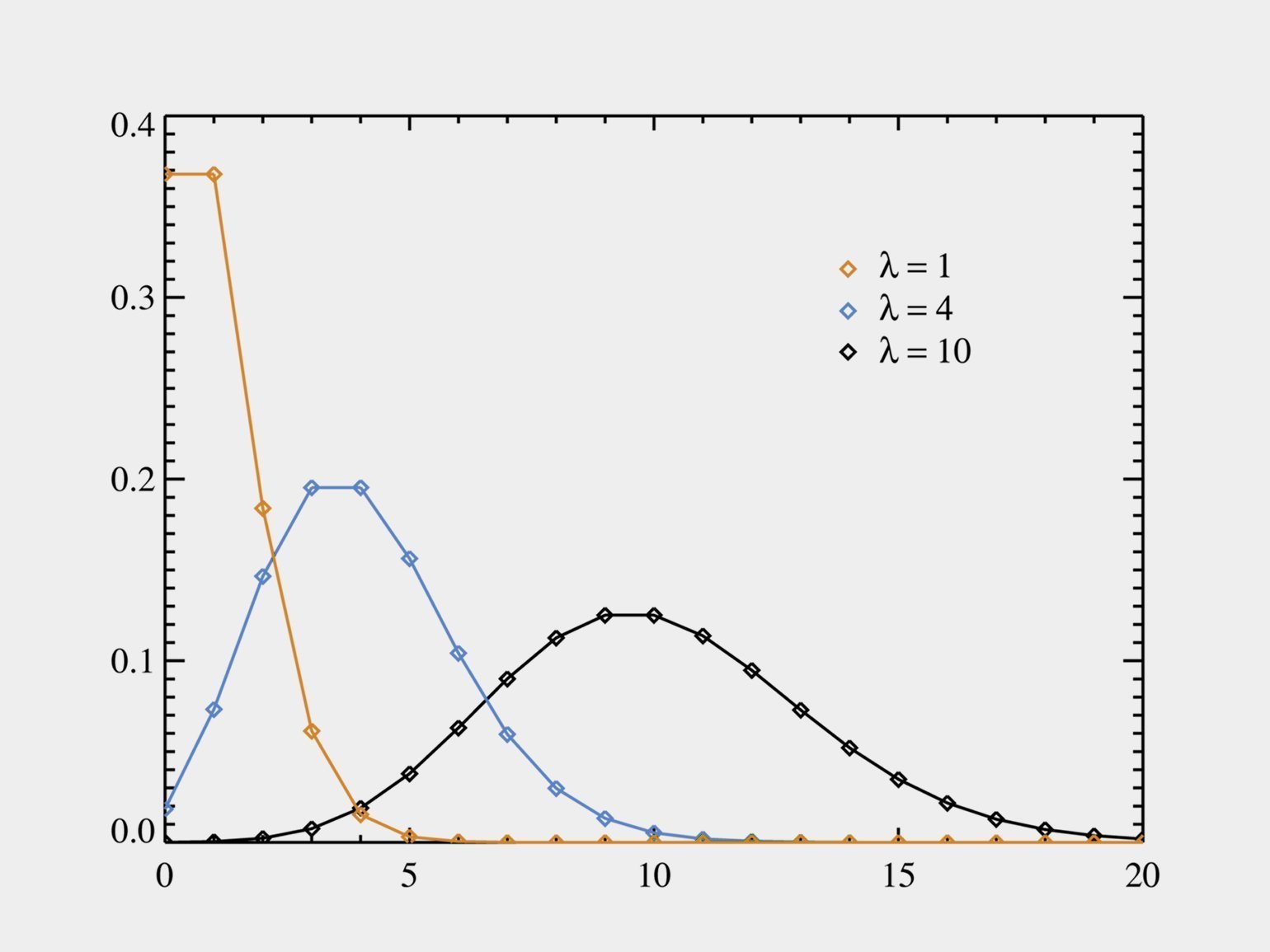
При ƛ = 10 горка Пуассона похожа на колокол Гаусса. Будьте внимательны!
Это и число посетителей в торговом центре, и количество голов, забитых футбольной командой, и скорость роста колонии бактерий.
Существуют и , в том числе довольно экзотические: Вигнера, Вейбулла, Коши. Они встречаются намного реже или преимущественно в каких-то специальных областях вроде квантовой физики. Тем не менее дата-сайентисту нужно знать графики, параметры и названия основных распределений, благо их не так много.
Структура органа
В оргструктуре Росстата имеются следующие подразделения:
- Управление международной статистики;
- Управление координации и развития статистического учета;
- Управление статистики предприятий;
- Управление национальных счетов;
- Управление разработки таблиц «затраты-выпуск» и статистики групп предприятий;
- Управление статистики строительства, инвестиций и жилищно-коммунального хозяйства;
- Управление статистики сельского хозяйства и окружающей природной среды;
- Управление статистики труда;
- Управление статистики уровня жизни и обследований домашних хозяйств;
- Управление сводных статистических работ и общественных связей;
- Управление статистики населения и здравоохранения;
- Управление статистики рыночных услуг;
- Управление цифрового развития;
- Управление национальной системы управления данными государственной статистики;
- Управление статистики образования, науки и инноваций;
- Управление статистики цен и финансов и другие.
В регионах имеются территориальные подразделения ведомства.
Назначение и освобождение главы службы от должности осуществляется Правительством РФ. Кандидатура одобряется Министром экономического развития. С 2018 года пост начальника ведомства занимает Павел Викторович Малков.
Генеральная совокупность
Давайте разберемся, на что в первую очередь обращать внимание перед началом любой исследовательской или аналитической работы, какие вообще данные следует использовать,
Для начала нам нужно четко обозначить, для какого множества объектов мы хотели бы получить результаты экспериментов или исследований. То есть, что мы будем считать генеральной совокупностью нашего исследования.
Генеральная совокупность — это множество всех объектов, относительно которых предполагается делать выводы в рамках конкретного исследования. Генеральную совокупность составляют все объекты, которые отвечают всем заранее заданным параметрам.
Почему это важно? Разберем на конкретных примерах
Пример 1
Хотим узнать средний рост у космонавтов, находившихся в космическом полете более 180 дней.
Так как под такое описание подходит небольшая группа людей (а именно космонавты, которые пробыли в полете более 180 дней), мы можем провести исследование с участием всех представителей этого класса. Они и будут составлять генеральную совокупность нашего исследования.
Пример 2
Хотим изучить, какой мультфильм является самым любимым у детей до 5 лет, живущих в Москве.
В данной ситуации абсолютно все дети в возрасте до 5 лет, которые живут в Москве, будут представлять генеральную совокупность для нашего исследования.
Очевидно, что в исследовании из Примера 1 мы можем измерить рост каждого космонавта и получить желаемый результат.
В Примере 2 все становится несколько затруднительнее: теоретически мы, конечно, можем опросить каждого ребенка из Москвы в возрасте до 5 лет, но это сложно реализуемая затея.
Что тогда делать? Можно взять только определенную часть генеральной совокупности, то есть сформировать выборку для исследования, а затем обобщить результаты, полученные на этой выборке, на всю генеральную совокупность.
Меры описательной статистики
Задача описательной статистики, как следует из названия, — дать хорошее описание данных. Она не для предсказаний, выводов или преобразований — только внешняя форма данных, измеренная в показателях.
Ключевые показатели, применяемые в описательной статистике (их ещё называют мерами или, если точнее, ), — это:
- Среднее: чаще всего вычисляется как среднее арифметическое. Просто складываем все значения, делим на их количество — и вуаля, средняя температура по больнице готова.
- Медиана: если выстроить все данные по возрастанию и найти середину этого ряда, это как раз и будет медиана. Одна половина из значений данных будет больше медианы, а другая — меньше.
- Мода: значение в наборе данных, которое встречается чаще всего. Запомнить очень легко: мода — самое популярное из значений, то, что «носят все».
Посмотрите это небольшое видео о среднем, медиане и моде на сайте Академии Хана — образовательного ресурса, который славится доходчивыми объяснениями. Там всё просто, на понятном русском языке.
Кроме трёх перечисленных, есть и другие статистические показатели — например, . Главная из них — дисперсия, о ней ниже. Все они нужны, чтобы понять, какие перед нами данные и о чём именно они рассказывают.